한눈에
- 어르신은 글자·버튼 중심의 배달 앱을 어려워한다(서울 70세 이상 이용률 7.7%, 자체 설문에서 42%가 “어렵다”). 그래서 전화하듯 말로 주문하는 앱을 만든 팀 프로젝트다. 나는 그중 어르신의 말을 알아듣고(STT) 무슨 뜻인지 파악하는(NLU) 두 AI 모델을 맡았다.
- 표준어에 맞춰진 음성인식은 노인 사투리에서 절반 가까이 틀린다(WER 50%). 그래서 방언 음성으로 다시 학습시켜 글자 오류율(CER)을 25.2%에서 6.9%로, 단어 오류율(WER)을 50.1%에서 18.7%로 끌어내렸다.
- 말을 글로 바꾼 뒤, 그 문장이 추천·가게선택·메뉴선택·주문확정 등 8가지 중 무슨 의도인지 분류한다(정확도 96.3%). 그 의도에 따라 다음 주문 단계로 넘어간다.
내가 맡은 범위
팀이 음성 주문 앱을 나눠 만들었고, 나는 시스템의 “귀와 이해” — 말을 글로 바꾸는 STT 모델과, 그 글의 의도를 읽는 NLU 모델을 데이터 수집부터 학습·평가까지 맡았다.
- STT 음성인식 모델 — 노인 사투리를 알아듣도록 Whisper를 방언 데이터로 파인튜닝.
- NLU 의도분류 모델 — 전사된 문장을 8가지 주문 의도로 분류해 대화 흐름에 넘김.
앱(안드로이드)과 서버(Node.js), 대화 흐름 제어(FSM), 가게 추천 챗봇(RAG·크롤링)은 다른 팀원들이 맡았다. 사용자가 말한 음성은 앱이 서버로 보내고, 서버에서 내 두 모델을 거쳐 의도가 정해지면 그 뒤 단계가 이어진다.
내가 내린 설계 결정
사투리에 맞춰 다시 가르치기 — Whisper LoRA 파인튜닝
표준어 위주로 학습된 음성인식은 어르신의 방언 섞인 발화에서 형편없다 — 그냥 Whisper-medium은 우리 방언 평가셋에서 단어 오류율(WER) 50.1%, 글자 오류율(CER) 25.2%로 절반 가까이 틀렸다. 그래서 AI-Hub의 중·노년층 한국어 방언 음성 1,167시간으로 추가 학습시켰다. 모델 전체를 다시 학습하면 무겁고 오래 걸려, LoRA(핵심 일부 층에 작은 행렬만 더해 학습하는 방법)로 전체의 약 1%만 학습해 학습 시간을 324시간에서 54시간으로 줄였다. 그 결과 WER은 50.1% → 18.7%, CER은 25.2% → 6.9%로 오류를 1/3 수준으로 줄였고, 같은 방언 평가셋에서 이 모델은 범용 음성인식(GPT-4o·Google)보다도 정확했다(WER 18.7 vs 37.7 vs 68.3).
특정 지역에 치우치지 않게 — 데이터 균등화
원본 방언 데이터는 여성과 특정 지역에 쏠려 있었다(남 27% : 여 73%). 그대로 학습하면 모델이 한쪽 발음에 치우친다. 그래서 나이(60–89세 노년층)·성별·5개 지역(경상·전라·강원·충청·제주)을 고르게 샘플링해 1,167시간 학습셋을 새로 구성했다(남 52% : 여 48%, 지역도 고르게). 덕분에 특정 지역 사투리에만 강한 모델이 되지 않게 했다.
폰에서 가볍게 돌리려고 — 모델 경량화
이 앱은 어르신의 휴대폰에서 가볍게 도는 것을 목표로 했다. 그래서 파인튜닝한 모델을 ONNX로 변환하고 INT8로 양자화(실수 가중치를 정수로 바꿔 크기·연산을 줄이는 방법)해 모바일에 맞게 경량화하는 작업까지 했다.
237문장을 21,875개로 — NLU 데이터 증강
의도 학습 데이터가 처음엔 237문장뿐이었다. 그대로는 모델이 다양한 말투를 못 버틴다. 그래서 사투리·맞춤법 오류·띄어쓰기 오류를 일부러 섞어 21,875문장으로 늘렸다(“짜장면 한 개랑 짬뽕 두 개 주세요” → “짱깨 둘 짬뽕 하나 주이소”처럼). 어르신과 방언 발화에 강건하도록 학습 데이터를 만들었다.
정확도만큼 속도도 — NLU 모델 선택
의도 분류 모델로 KLUE-RoBERTa-large와 KoBigBird-RoBERTa-large를 같은 데이터로 비교했다. 정확도는 96.3% 대 96.0%로 비슷했지만, 초당 처리량이 183문장 대 32문장으로 차이가 컸다. 실시간 대화 응답이 중요하므로 정확도가 비슷하면서 훨씬 빠른 KLUE-RoBERTa를 채택했다. 최종 8개 의도 분류 정확도는 96.3%다.
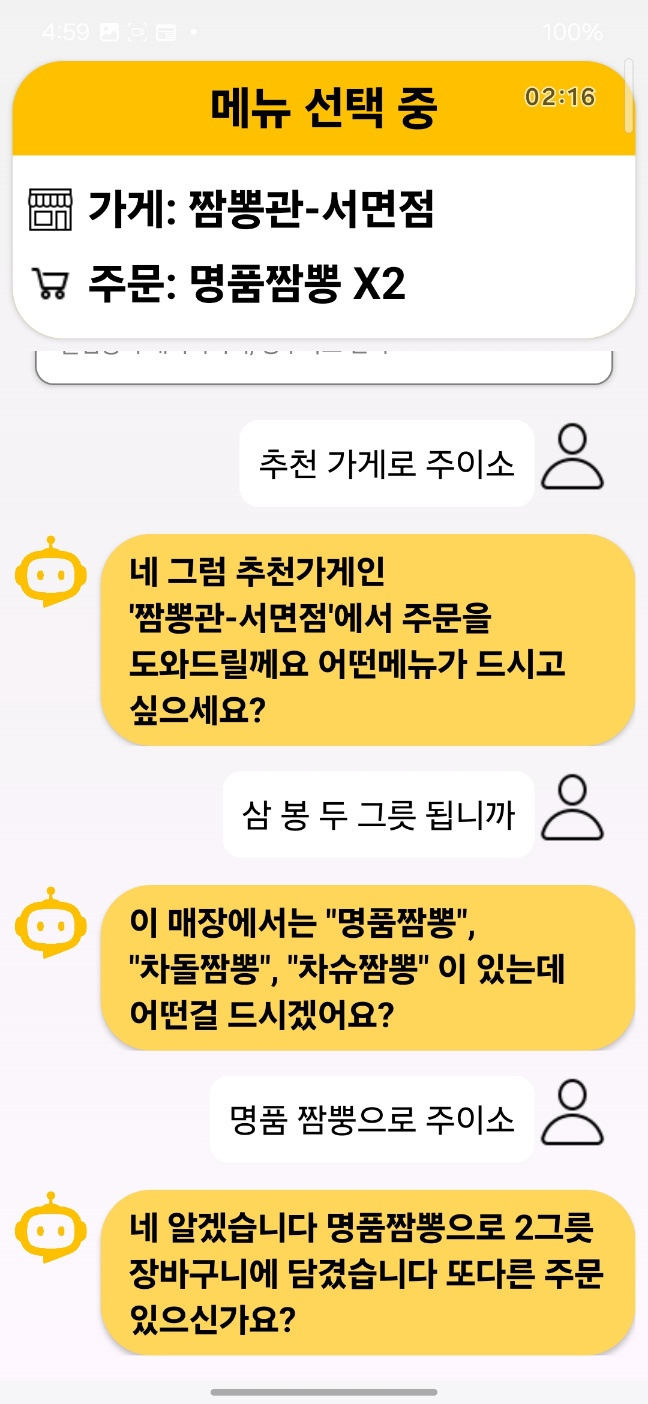
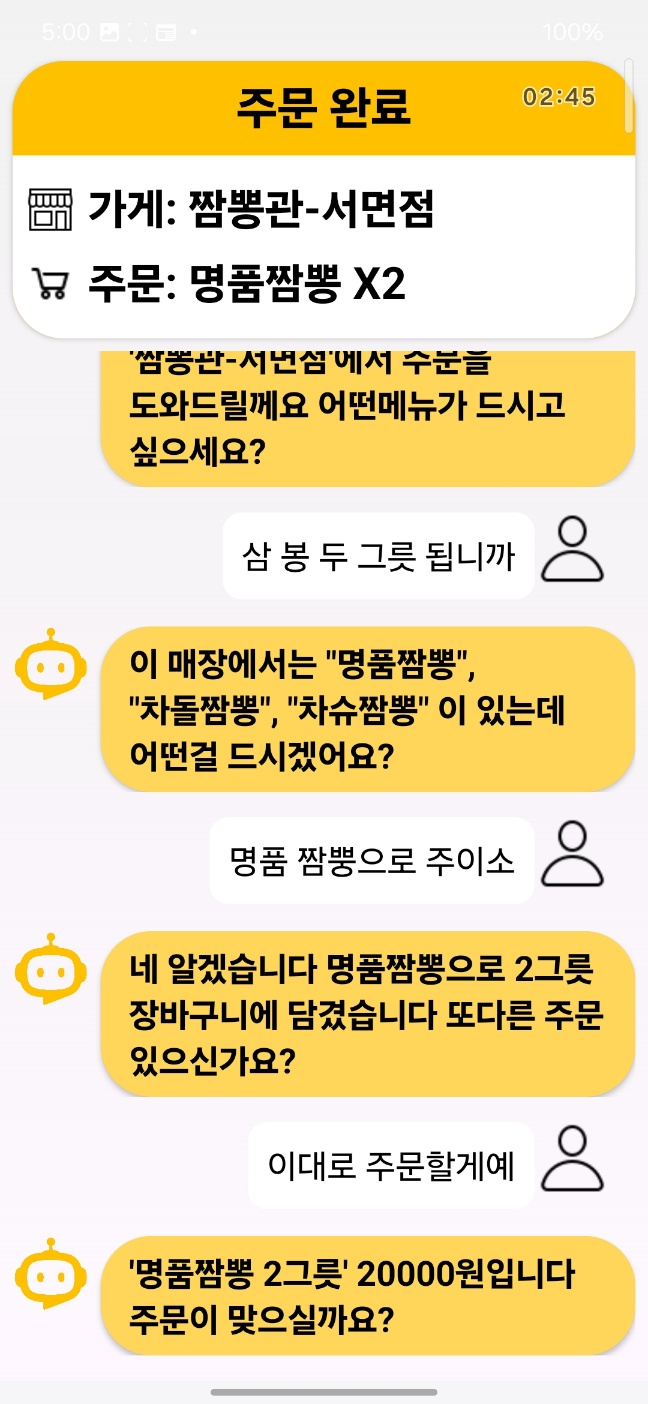
대화 흐름 — 사용자가 말한 문장이 글로 전사되고(STT), 그 의도에 따라 메뉴 선택에서 주문 완료까지 이어진다(NLU). 답변 문구·주문 상태 표시·UI는 팀원 몫(RAG·FSM·앱)이다.
정직하게 — 내가 한 일
이 프로젝트에서 내가 만든 것은 STT·NLU 두 모델이고, 데이터 구축·파인튜닝·평가까지를 맡았다. 모델 코드는 AI를 페어로 구현했다. 앱·서버·대화 흐름 제어(FSM)·가게 추천 챗봇(RAG/LLM·크롤링)은 팀원들이 맡았다.
- 성능 수치(CER·WER·정확도)는 프로젝트 자체 평가셋으로 측정한 값이다.
- 여기서 만든 방언 Whisper 모델은 이후 CareLink의 음성 호출 인식에 재사용했다.